
Content models evolve and content relationships change. As they change, we must ensure content models remain easy to read and understand. These design guidelines help modellers arrange, label and standardise their work.
We stand upon some excellent design thinking by Scott Ambler. He applied design guidelines to software development many years ago. I’ve simply applied some of that thinking within the context of content modelling.
Always indicate cardinality.
Don’t let the reader think or make open assumptions about cardinality. If the content relationship cardinality is known, make it clear. This guideline kicks into action when you hit the design and implementation content modelling phases. For the conceptual content model, it’s okay to keep things simple and less expressive. We cover cardinality in content relationships early in the content modelling series.
Avoid open cardinality of *. Always favour 0..* or 1..*
The * is ambiguous. Does it mean 1-to-many, or 0-to-many. As we add more detail, don’t make me think. Make your multiplicity statements explicit. This becomes even more important as you move towards implementation content models.
Question cardinality with minimums and maximums.
No one understands your business better that you. That doesn’t mean you should paint yourself into a design corner with minimums and maximums today, making it harder to back out of tomorrow.
Consider this example. A recruitment firm specialises in placing experienced research scientists. It decides today that all its candidates must have at least two academic degrees. It also believes candidates have between three and ten permanent posts. The modeller decides to bake these minimum and maximum constraints into the content model like so:

These sorts of decisions are prescriptive but come with associated pros and cons. We can build authoring tools enforce these rules at the point of content entry. We can prevent creating candidates that don’t satisfy these rules. Style guidelines are written to communicate this. APIs are built with this in mind. We align designers, developers, partners to conform to these shared standards. In short, checks are made at each and every point to enforce content integrity. This is all good news…
…until the business decides to change its mind. Then every optimisation we’ve made based upon these assumptions becomes a legacy feature overnight. We now have to undo what’s been done. The model changes and we need have to manage the impact. We now need to revisit every touchpoint to enforce this new model constraint and perform a cost/impact analysis for change.
Be vigilant. Question over prescriptive minimums and maximums within the context of future-proofing your content model from changing business requirements.
Replace relationship lines with attribute types.
If I was to highlight a critical design guideline for increasing readability and reducing the complexity of content models, then this would be amongst my top five. It’s a great guideline for reducing design clutter within your content models. Here’s how it works.
We have two content types connected in a aggregation content relationship. Profile (whole) contains a Video (part). Within our content model it looks something like this:
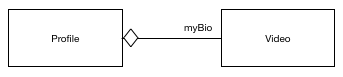
Video is a common content type. It’s part of a Profile and countless other content types. Commonplace content types such a Video are standard types such as Text, Date and Number. So instead of every content type that has a Video engaging in a aggregation relationship and cluttering the content model, we make the Video a type an attribute within whole. Our content model now looks like this:

Simple.
Focus on the whole/part and aggregation content relationships.
Pay specific attention to which content types own other content types. Keep an eye on your content model as the number of content types increase. You very quickly have an network of inter-connected content types.
Content types spawn content items. Lots of them. At this point ownership becomes a bigger deal. Be clear on the life and death aspects of content. You should be able to walk through a content model and see how creation and expiration concerns will cascade through your information space. Design for it upfront and manage it going forwards.
Dependency indicates need for a relationship.
The dependency is the weakest content relationship. Typically, dependencies need to be strengthened as you move from conceptual, into design and then into implementation. If we have two content types that depend upon one another, but you cannot strengthen it, is there really a relationship there. Furthermore, why add cost and maintain it? Understand the relationship, model it, or drop it.
Do Not Model Every Single Dependency.
Content models can get very big. You can break them up into content modules and apply modularity to ensure that they are highly cohesive and loosely coupled. But even within a content module, there is a temptation to model every dependency between content types. Specifically, as you move into more detailed design and into implementation. Resist this.
Instead, model only the content relationships that add to the communication value of your content model. Otherwise, you will quickly clutter your content model with additional lines. This will only serve to make you content model harder to read and understand.
Find that balance between the essential characteristics of your content model. It’s a subjective call, but make that call.
Use CamelCase naming for content relationships.
We spoke about content attribute names when we covered types and attributes. For content relationships naming, the same rules apply. Use camel case and favour:
- publishDate, lastName, lastLogIn, recipe (see example above with myBio within Profile)
over
- publishdate, publish_date, PublishDate, or Publish_Date
Try not to to use consecutive capital letters, so favour
- newsRssFeed
over
- newsRSSFeed
Try not to shorten names because it’s ugly and things get lost in translation, so favour:
- financeManager
over
- financeMgr
