
Content types rarely live in isolation. They have relationships. A content model is nothing more than a system of interconnected content types. It’s never just an article, an account, a film, a car. In fact, the relationships that exist between content types are just as important as the content types themselves. Let’s explore what we mean by content relationships.
The Content Type
A content type is an information asset. It has a collection of attributes that collectively define what it is. Here is an example of an Article content type.

Just by looking at the attributes you get a pretty good feel for the essential characteristics of an Article. Now let’s take this a little further. Imagine we run a fashion and lifestyle business that engages with its global customer base through a monthly magazine. The Magazine is another key information asset, or content type, within our business. So how does a Magazine relate to an Article?
Content Relationships
Where attributes define the structure within a content type; relationships express the way content types to relate to each other. In order to determine how content types relate to one another, we must go back to the business and ask a few clarifying questions. Do magazines exclusively own their articles? Does it make sense for an article be shared across multiple magazine titles? When a magazine expires can you still access its articles? If so, who is the new article owner? If not, do we trash the article when the magazine expires? Can articles be linked other articles? Can articles be linked to magazines other than the magazine there were first published within?
Only by asking and answering these questions can we narrow down on the right kind of relationship that should exist between our Magazine and Article content types. All too often these questions are not asked upstream and so development teams are left to make assumptions. Invariably we see content systems built on best endeavours to fill these requirement gaps. Let’s stop doing this and give our creative and engineering teams a better steer.
Just before we get into content relationship is important to note that this isn’t greenfield thinking. We are drawing upon design and modelling expertise that has been tried and tested, for many decades, in the data and software industry. We are just applying it within the field of content design. All these relationships have names and semantics that are well understood. Let me introduce you to three of the most common relationship types using our Magazine and Article content types as examples.
Dependency Relationship
In the early stages of content modelling, when you know there is a relationship between two content types but are not quite sure of the extent of it, you can express that through a simple dependency relationship. As a modeller, at this point in time, let it be known that Magazine and Article are related. That’s all we’re saying.
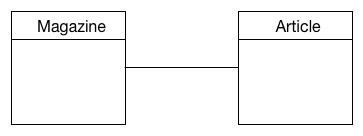
The dependency relationship is deliberately weak on semantics. It defers decision making until we know more about the domain under study. We are happy express that two content types are related at this point.
Whole/Part Relationship
This relationship is all about ownership. What is the whole? What is the part? If the relationship between our Magazine and Article content types is expressed as a whole/part, the business is setting a couple of clear expectations:
1) A magazine exclusively owns all its articles.
2) When a magazine is destroyed, all it’s articles are destroyed.
The whole/part relationship brings important lifetime dependency characteristics between content types into play. The decision to model content types as whole/part comes from deeper analysis and discussions with the business. Only then are we better positioned to move from the weaker semantics of the dependency relationship to the much stronger semantics of whole/part.
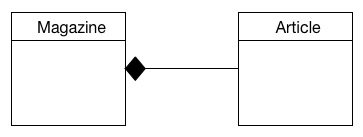
The black diamond is on the whole (Magazine) and the other end is the part (Article).
Aggregation Relationship
Aggregation is also a content relationship about ownership, but with a slightly different focus. Instead of articles being owned by the magazine, aggregation loosens that a little to merely communicate access to articles. With aggregation:
1) Magazines do not exclusively own articles.
2) Articles live on when a magazine is destroyed.
Aggregation breaks the lifecycle dependency between content types. As such, a magazine acts more like a container for articles that can be added and removed where appropriate. How articles are created and destroyed is less of concern for the magazine.
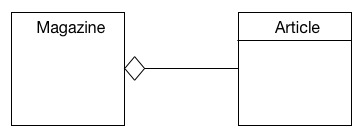
The white diamond is on the container (Magazine) and the other end is the content type being aggregated (Article).
Putting it altogether
Let’s take a step back and playback what our definition of a content model:
A content model is a formal representation of structured content as a collection of content types and their inter-relationships.
Content types are important, but so too are the relationships between them. During the early phases of content modelling it’s okay just to declare that there is a relationship between two content types. We don’t need to convey much more than that, so we draw a line between them and with have a dependency relationship.
As we learn more, we find that the business wants to express richer semantics between its content types. For example, in the film industry where there are series and episodes, the business wants the content model to reflect that episodes do not make sense outside the context of series. No series, no episode. One way to enforce these richer semantics within the content model is through the whole/part relationship. When the series is destroyed, so too are all its episodes. Also, every episode (part) is always member of a series (whole). The dependency relationship is not suppose to capture these richer semantics but the whole/part relationship does.
Now turning our attention to publishers that create articles for many titles and formats, such as magazines, newspapers, blogs, the business expects to reuse and repurpose articles. In this business model, an article does not belong exclusive to single title. So we choose to impose a different set of design constraints by selecting the aggregation relationship. Here an article is accessible from magazines, newspapers, blogs or any other title/format. In doing so, we are clearly expressing through the aggregation relationship that if we remove an article from a magazine it will still be accessible by other titles. Good job really.
Summary
There are many different kinds of relationships that can be applied within a content model to add both structure and meaning. Structure and meaning make our content intelligent. Some relationships impose weak semantics (dependency). Other express stronger semantics, such as whole/part and aggregation.
Content relationships enable modellers to capture and enforce business relationships between information assets, and build that thinking into our content models. We do this to bring these important discussions and decisions closer to the business. The goal is communication around content, whether that’s top-down, bottom-up, inside-out, outside-in, it doesn’t matter. We just want everyone to get more involved and make sense of the content they have. Only then do we have a foundational core upon which to design and build sustainable content-driven experiences.
Where next?
